 集群原理篇
集群原理篇
本文内容是 redis 3.0+
# 主要特性
# 设计目标
Redis Cluster 是 Redis 的分布式实现,在设计中具有以下目标,按重要性顺序排列:
- 高性能和线性可扩展性可以多达 1000 个节点。不需要任何代理,使用异步复制,并且不对
values进行合并操作。 - 可接受一定的写丢失:系统尝试(以最佳方式)保留来自与大多数主节点连接的客户端的所有写操作。通常,在一些小窗口中,已确认的写入可能会丢失。当客户端位于少数分区时,丢失已确认写入的窗口更大。
- 可用性:Redis Cluster 在以下场景下集群总是可用:大部分 master 节点可用,并且对少部分不可用的 master,每一个 master 至少有一个当前可用的 slave。更进一步,通过使用 replicas migration 技术,当前没有 slave 的 master 会从当前拥有多个 slave 的 master 接受到一个新 slave 来确保可用性。
# 写安全
# 异步复制场景
在 master 复制到 slave 时, master 宕机,然后 salve 被选为 master ,这个时候 redis cluster 不会去 merge 原 master 的数据,而是认为这个 slave 就是最新的数据。在 master 重启后,master 会变为 slave,同步新选出的 master 的数据,导致数据丢失。
# 例子
一个原因是因为 redis cluster 使用异步复制。这意味着在写入期间会发生以下情况:
- client 将数据写入 B。
- B 响应给 client 写入成功。
- B 将写入传播到他的副本节点 B1、B2 和 B3。
所以可以看到,B 不会等待副本节点的确认消息,所以存在着一定延迟,如果在同步给从节点前 B 挂了,然后从节点(没有收到新写入的)被选为主节点,那么这个写入将会永远丢失了。
# 解决方案
- 将每次 client 的写操作都落盘后再响应给客户端成功。不过性能很低。
- 使用 WAIT 命令实现,这个命令可以实现同步复制,让从节点都写入后再响应成功。但是这个不能够保证强一致性(部分节点没有写入成功,然后没有写入成功的节点被选为了主节点)。
# 分区异常场景
master因为分区原因不可用(unreachable)
该 master 被某个 slave 替换(failover)
一段时间后,该 master 重新可用
在该 old master 变为 slave 之前,一个 client 通过旧的(过期的)的路由表对该节点进行写入。
# 例子
在分布式环境下,我们假设有 A、B、C、A1、B1、C1 6 个节点的主从集群模式,并且存在客户端一个 Z, 假设 B 节点挂了,并且 B 的所在区域和 Z 一样。 Z 还是可以往 B 写入数据,但 B 和 A、C 无法机器通讯了,这时 Z 还继续往 B 写入数据,然后 B1 被选举成了 master 了。就导致 B 网络恢复后数据丢失。
# 解决方案
我们可以设置一个节点超时时间(cluster-node-timeout)来减少丢失的数据,再如果 B 超时后就不再接受写入请求了,这牺牲了可用性。
# 可用性
Redis Cluster在少数机器分区侧不可用。在多数机器分区侧,假设由多数机器分区这边存在不可达的 master, 并且 master 在这边有一个 slave,cluster 将会在 NODE_TIMEOUT 外加重新选举所需的一小段时间(通常1~2秒)后恢复可用(将 slave 变为 master)。
这意味着,Redis Cluster被设计为可以忍受一小部分节点的故障,但是如果需要在大网络分裂事件中(比如发生多分区故障导致网络被分割成多块,且不存在多数机器 master 分区)保持可用性,它不是一个合适的方案(不要尝试在多机房间部署 redis cluster,这不是 redis cluster 该做的事)。
假设一个 cluster 由 N 个 master 节点组成并且每个节点仅拥有一个 slave,在多数侧只有一个节点出现分区问题时,cluster 的多数侧可以保持可用,而当有两个节点出现分区故障时,只有 1-(1/(N*2-1)) 的可能性保持集群可用。 也就是说,如果有一个由 5 个 master 和 5 个 slave 组成的 cluster,那么当两个节点出现分区故障时,它有 1/(5*2-1) = 11.11%的可能性发生集群不可用。
Redis cluster 提供了副本迁移的特性,它自动将副本节点转为孤立的 master 节点的副本节点(没有副本节点的 master)。因此,在每次故障事件中,集群可能会重新配置副本布局,以更好地抵抗下一次故障。
# 性能
Redis Cluster不会将命令路由到其中的 key 所在的节点,而是向 clien t发一个重定向命令 (MOVED) 引导 client 到正确的节点。最终 client 会获得一个最新的 cluster(hash slots 分布) 信息,以及命令中的 keys 应该被打到哪个节点,因此 clients 就可以获得正确的节点并用来继续执行命令。
因为 master 和 slave 之间使用异步复制,节点不需要等待其他节点对写入的确认(除非使用了WAIT命令)就可以回复 client。 同样,因为multi-key命令被限制在了临近的 key (即同一个hash slot内的key,或者从实际使用场景来说,更多的是通过hash tag定义为具备相同hash字段的有相近业务含义的一组keys),所以除非触发resharding,数据永远不会在节点间移动。
普通的命令(normal operations)会像在单个redis实例那样被执行。这意味着一个拥有 N 个 master 节点的Redis Cluster,你可以认为它拥有 N 倍的单个 Redis 性能。同时,query 通常都在一个 round trip 中执行,因为 client 通常会保留与所有节点的持久化连接(连接池),因此延迟也与客户端操作单台 redis 实例没有区别。
在对数据安全性、可用性方面提供了合理的弱保证的前提下,提供极高的性能和可扩展性,这是Redis Cluster的主要目标。
# 其他特性
database 限制为 0,并且不支持多数据库,select 命令禁用
> select 1 (error) ERR SELECT is not allowed in cluster mode1
2限制 multi key 命令,不能同时 set 不在一个哈希槽的命令。
> mset aaaa 1 bbbb 2 (error) CROSSSLOT Keys in request don't hash to the same slot1
2无需 merge 操作,在 resharding 的时候不需要处理 key 冲突,因为 key 都会分配到不同的哈希槽,并且能够保证机器上面的 key 都是不冲突的。
# 主要模块
# Key 的分布算法与哈希槽
Redis-cluster 没有使用一致性hash,而是引入了 哈希槽 的概念。Redis Cluster 中有 16384() 个哈希槽,Cluster中的每个节点负责一部分hash槽(hash slot),每个 key
通过下面的算法计算出所属槽:
HASH_SLOT = CRC16(key) mod 16384
CRC16 ,可以参考我写的一个文章:CRC16,算法的参数如下
- 模式: XMODEM
- 位数: 16 bit
- Poly: 1021 (That is actually x^16 + x^12 + x^5 + 1)
- 初始值: 0000
- 出入高低位反转: False
- 输出高低位反转: False
- 异或常量: 0000
- 示例: "123456789": 31C3
# 哈希标签(Hash Tag)
Hash tags提供了一种途径,用来将多个(相关的)key分配到相同的hash slot中。这是 Redis Cluster 中实现 multi-key 操作的基础。
hash tag 规则如下,如果满足如下规则,{ 和 } 之间的字符将用来计算 HASH_SLOT,以保证这样的 key 保存在同一个slot中。
- key包含一个
{字符 - 并且 如果在这个
{的右面有一个}字符 - 并且 如果在
{和}之间存在至少一个字符
例如:
- 两个键 {user1000}.following 和 {user1000}.followers 将散列到相同的散列槽,因为只有子字符串 user1000 将被散列以计算散列槽。
- 对于键 foo{}{bar},整个键将像普通 key 一样被散列,因为第一次出现的 { 后面是右侧的 },中间没有字符。
- 对于键 foozap,子字符串
{bar将被散列,因为它是第一次出现 { 和第一次出现 } 之间的子字符串。 - 对于键 foo{bar}{zap},子字符串
bar将被散列,只看第一个。 - 从算法中得出的结论是,如果密钥以 {} 开头,则可以保证将其作为一个整体进行散列。这在使用二进制数据作为键名时很有用。
具体计算逻辑代码
unsigned int keyHashSlot(char *key, int keylen) {
int s, e; /* start-end indexes of { and } */
for (s = 0; s < keylen; s++)
if (key[s] == '{') break;
/* No '{' ? Hash the whole key. This is the base case. */
if (s == keylen) return crc16(key,keylen) & 0x3FFF;
/* '{' found? Check if we have the corresponding '}'. */
for (e = s+1; e < keylen; e++)
if (key[e] == '}') break;
/* No '}' or nothing between {} ? Hash the whole key. */
if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF;
/* If we are here there is both a { and a } on its right. Hash
* what is in the middle between { and }. */
return crc16(key+s+1,e-s-1) & 0x3FFF;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 集群信息
查看集群信息
redis-cli -p 7001 cluster nodes
-------------
7a8c6effe2f901163af3215a9cc14d202a7adf7a 127.0.0.1:7006@17006 slave dfb854284143d158bedc1cbf797b12433e650c70 0 1658664577665 3 connected
9ad92eeb0d29e2366b6374176214d2c06b82ba23 127.0.0.1:7002@17002 master,fail - 1658664544331 1658664541000 2 disconnected
a973a2e50bdaecd901928fd627ab377df31e19d5 127.0.0.1:7004@17004 slave 1b09694a6d5c151479086c13a60636614121666e 0 1658664576659 7 connected
1b09694a6d5c151479086c13a60636614121666e 127.0.0.1:7001@17001 myself,master - 0 1658664578000 7 connected 0-5466 10923-10926
917d27469a8aafbc7e11ca8ceadfe911d67664e5 127.0.0.1:7005@17005 master - 0 1658664578673 8 connected 5467-10922
dfb854284143d158bedc1cbf797b12433e650c70 127.0.0.1:7003@17003 master - 0 1658664575648 3 connected 10927-16383
2
3
4
5
6
7
8
9
- 节点 ID :例如
3fc783611028b1707fd65345e763befb36454d73。 ip:port:节点的 IP 地址和端口号, 例如127.0.0.1:7000, 其中:0表示的是客户端当前连接的 IP 地址和端口号。flags:节点的角色(例如master、slave、myself)以及状态(例如fail,等等)。- 如果节点是一个从节点的话, 那么跟在
flags之后的将是主节点的节点 ID : 例如127.0.0.1:7002的主节点的节点 ID 就是3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e。 - 集群最近一次向节点发送 PING (opens new window) 命令之后, 过去了多长时间还没接到回复。
- 节点最近一次返回
PONG回复的时间。 - 节点的配置纪元(configuration epoch):详细信息请参考 Redis 集群规范 (opens new window) 。
- 本节点的网络连接情况:例如
connected。 - 节点目前包含的槽:例如
127.0.0.1:7001目前包含号码为5960至10921的哈希槽。
# Cluster Bus 端口
每个 Redis 集群节点都需要两个开放的 TCP 连接:
- 一个用于服务客户端的 Redis TCP 端口,例如 6379。
- 另一个为集群总线(cluster bus)的端口。
默认情况下,集群总线端口设置为服务端口加 10000(例如 16379),但是,您可以用 cluster-port 配置覆盖它。
cluster 之间的使用特殊的二进制协议进行节点到节点的数据交换,它使用很少的带宽和处理时间在节点之间交换信息。
# 集群拓扑
Redis 集群是一个完整的网格,其中每个节点都使用 TCP 连接与每个其他节点连接。 在 N 个节点的集群中,每个节点都有 N-1 个传出 TCP 连接和 N-1 个传入连接。 这些 TCP 连接一直保持活动状态,不是按需创建的。当一个节点期望一个 pong 回复以响应集群总线中的 ping 时,在等待足够长的时间以将该节点标记为不可达之前,它将尝试通过从头开始重新连接来刷新与该节点的连接。 而 Redis Cluster 节点形成网络拓扑,节点使用 gossip 协议和配置更新机制,以避免在正常情况下节点之间交换过多的消息,因此交换的消息数量不是指数级的。
# 集群握手
节点总是接受集群总线端口的链接,并且总是会回复ping请求,即使ping来自一个不可信节点。但是如果发送节点被认为不是当前集群的一部分,他发送的包将被忽略。
节点认定其他节点是当前集群的一部分有两种方式:
如果一个节点出现在了一条
MEET消息中。一条meet消息非常像一个PING消息,但是它会强制接收者接受一个节点作为集群的一部分。节点只有在接收到系统管理员的如下命令后,才会向其他节点发送MEET消息:CLUSTER MEET ip port1如果一个被信任的节点
gossip了某个节点,那么接收到gossip消息的节点也会那个节点标记为集群的一部分。也就是说,如果在集群中,A知道B,而B知道C,最终B会发送gossip消息到A,告诉A节点C是集群的一部分。这时,A会把C注册未网络的一部分,并尝试与C建立连接。
这意味着,一旦我们把某个节点加入了连接图(connected graph),它们最终会自动形成一张全连接图(fully connected graph)。这意味着只要系统管理员强制加入了一条信任关系(在某个节点上通过meet命令加入了一个新节点),集群可以自动发现其他节点。
# 请求重定向
Redis cluster采用去中心化的架构,集群的主节点各自负责一部分槽,客户端如何确定key到底会映射到哪个节点上呢?这就是我们要讲的请求重定向。
# moved 重定向
通过下面命令都可以看到集群的槽分布情况。
cluster nodes
cluster shards
cluster slots
2
3
moved 重定向就是 redis cluster 的 node 在收到客户端的命令后,会先计算出是不是当前节点的哈希槽,如果不在,则会响应 MOVED,比如如下命令:
127.0.0.1:7001> cluster keyslot aaaaa
(integer) 13356
127.0.0.1:7001> get aaaaa
(error) MOVED 13356 127.0.0.1:7003
127.0.0.1:7001>
2
3
4
5
可以看到提示我们在 7003 那个节点,并且哈希槽为 13356。注意:如果使用的 redic-cli -c 命令连接会自动进行重定向执行。
# Asking 重定向
asking 重定向发生在哈希槽迁移过程中,如果访问的哈希槽已经迁移到新的节点,那么就会返回一个 ASK ,然后客户端使用 Asking 的方式去迁移后的节点执行命令。
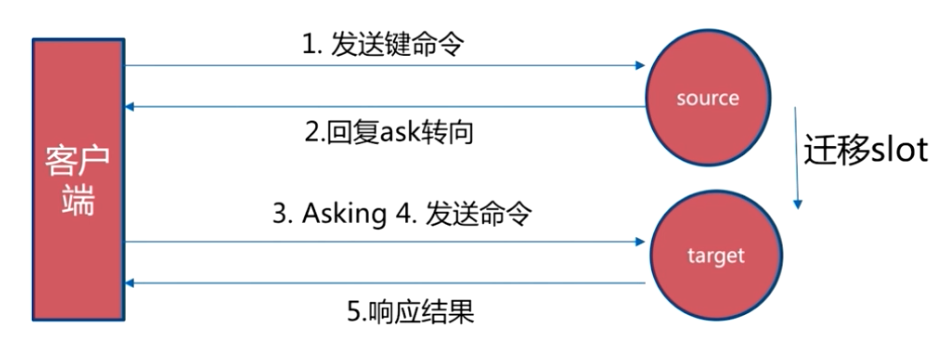
为什么有 moved 还有要 ask ,直接都用 moved 不好吗?
Moved 代表着永久移动到了对应的节点,client 可以放心的更新槽对应的节点。但是 Asking 代表着需要 client 每次都去先访问旧的节点,并且不更新本地槽的映射,直到看到 Moved 了才更新。
# 优秀的客户端的做法
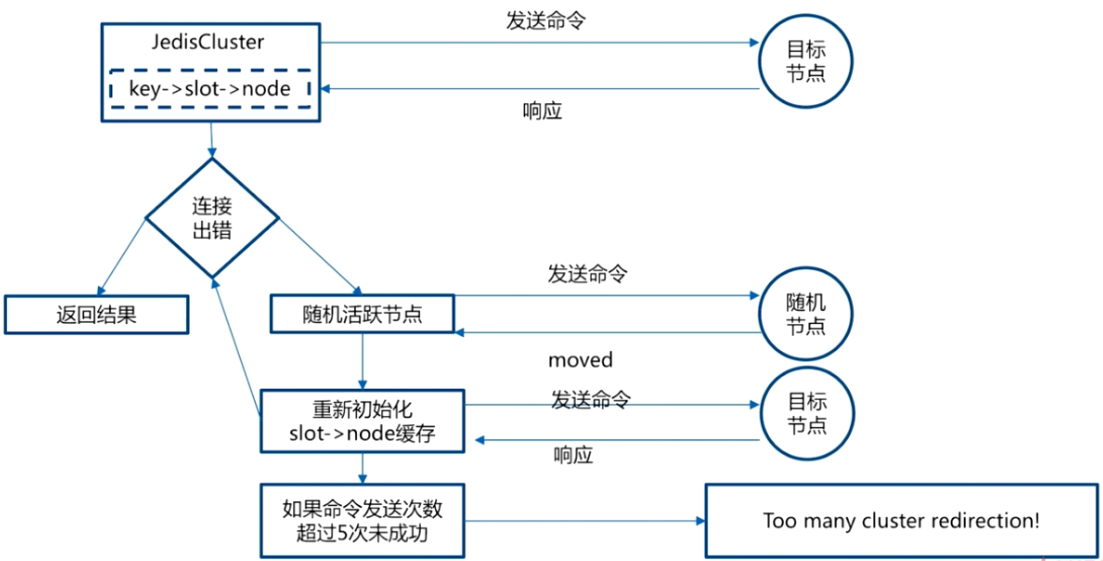
为了提高效率,Redis 集群的客户端应该维护哈希槽与节点的映射关系,这份配置如果不是最新时则更新到最新配置,JedisCluster 就是这个方式实现的。
通常情况下需要在下面两个场景更新:
- client 启动时
- client 收到 MOVED 时。
查看当前集群的哈希槽分布情况
127.0.0.1:7001> cluster slots
1) 1) (integer) 5461
2) (integer) 10922
3) 1) "127.0.0.1"
2) (integer) 7002
4) 1) "127.0.0.1"
2) (integer) 7005
2) 1) (integer) 0
2) (integer) 5460
3) 1) "127.0.0.1"
2) (integer) 7001
4) 1) "127.0.0.1"
2) (integer) 7004
3) 1) (integer) 10923
2) (integer) 16383
3) 1) "127.0.0.1"
2) (integer) 7003
4) 1) "127.0.0.1"
2) (integer) 7006
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
cluster slots 返回的哈希槽分布情况不一定覆盖了全部的哈希槽(配置错误),这个时候需要空 NULL 填充没有哈希槽的节点。
JedisCluster 实现逻辑:
# 集群容灾
# 心跳和 gossip 消息
Redis Cluster 节点不断地交换 ping 和 pong 数据包。这两种报文结构相同,都携带重要的配置信息。唯一的实际区别是消息类型字段。我们将 ping 和 pong 数据包一起称为心跳数据包。
一般情况下,节点发送一个 ping 都会要求接收方回复一个 pong 消息,但是在更新配置的时候节点会直接发广播 pong 消息。
通常一个节点每秒随机会 ping 几个节点,因此每个节点发送的 ping 数据包(和接收的 pong 数据包)的总数是一个常数,与集群中的节点数量无关。
但是,每个节点都确保在超过一半的 NODE_TIMEOUT 时间的情况下 ping 所有未发送 ping 或接收到 pong 的其他节点。在 NODE_TIMEOUT 过去之前,节点还尝试与另一个节点重新连接 TCP 链接,以确保节点不会仅仅因为当前 TCP 连接出现问题而被认为是不可访问的。
但是,在节点当已知的其他节点中,如果有超过 NODE_TIMEOUT/2 的时间没有收到他的 PONG 消息,或者没有对他发起过 PING,都将会再次发送一个 PING 消息。
如果 NODE_TIMEOUT 设置为一个小数字并且节点数 (N) 非常大,那么全局交换的消息数量可能会很大,因为每个节点都会给 NODE_TIMEOUT/2 的时间未收到消息的节点发送一个 PING 消息,所以每 NODE_TIMEOUT/2 时间内都会给其他节点都发一次消息。
例如,在一个节点超时设置为 60 秒的 100 个节点集群中,每个节点将尝试每 30 秒发送 99 次 ping,总 ping 数为每秒 3.3 次。乘以 100 个节点,即在整个集群中每秒 330 次 ping。请注意,即使在上面的示例中,每秒交换的 330 个数据包也平均分配给 100 个不同的节点,因此每个节点接收的流量是可以接受的。
# 心跳时机
Redis节点会记录其向每一个节点上一次发出ping和收到pong的时间,心跳发送时机与这两个值有关。通过下面的方式既能保证及时更新集群状态,又不至于使心跳数过多:
- 每次 Cron 向所有未建立链接的节点发送 ping 或 meet
- 每1秒从所有已知节点中随机选取5个,向其中上次收到 pong 最久远的一个发送 ping
- 每次 Cron 向收到 pong 超过 timeout/2 的节点发送 ping
- 收到 ping 或 meet,立即回复 pong
# 心跳包的内容
typedef struct {
char sig[4]; /* 签名,固定为 "RCmb" */
uint32_t totlen; /* 报文长度 */
uint16_t ver; /* 协议版本,当前是 1. */
uint16_t port; /* redis server 的 tcp 端口 */
uint16_t type; /* 消息的类型 */
uint16_t count; /* 用于一些特殊类型的消息,不是每类消息都有 */
uint64_t currentEpoch; /* 挂载着分布式算法 */
uint64_t configEpoch; /* 挂载着分布式算法 */
uint64_t offset; /* 复制的偏移量*/
char sender[CLUSTER_NAMELEN]; /* 发送消息的节点的名称 */
unsigned char myslots[CLUSTER_SLOTS/8]; /* 节点携带的哈希槽信息 */
char slaveof[CLUSTER_NAMELEN];
char myip[NET_IP_STR_LEN]; /* 发送放的 ip 地址,如果没有则为 0 */
uint16_t extensions; /* 随此数据包一起发送的扩展数 */
char notused1[30]; /* 保留数据字段 */
uint16_t pport; /* 如果是 TLS 节点,则这里就是明文的端口 */
uint16_t cport; /* 集群总线端口默认是 port + 10000 */
uint16_t flags; /* 发送节点的标识 */
unsigned char state; /* 发送消息的节点的视角看的集群的状态 */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data;
} clusterMsg;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
nodeId节点的唯一 ID,在创建集群节点的时候自动分配的 160 bit 的随机字符串。- 发送节点的
currentEpoch和configEpoch字段,用于挂载 Redis Cluster 使用的分布式算法。 flags,指示节点是否是副本、主节点和其他 1 bit 的信息。myslots,发送消息的节点的哈希槽信息,为一个 bitmap。- server 和 cluster bus 的端口信息。
state从发送者的角度来看集群的状态(down 或 ok)。slaveof发送节点的主节点 ID(如果它是副本)。
其中 PING、PONG 类型的数据包中,包含了 gossip 部分的数据,数据结构如下:
typedef struct {
char nodename[CLUSTER_NAMELEN];
uint32_t ping_sent;
uint32_t pong_received;
char ip[NET_IP_STR_LEN]; /* 上次看到它的IP地址 */
uint16_t port; /* 上次看到它的端口 */
uint16_t cport; /* 上次看到它的集群端口 */
uint16_t flags; /* 上次看到他的节点的 flags 信息 */
uint16_t pport; /* 上次看到它的纯文本端口(TLS 模式) */
uint16_t notused1;
} clusterMsgDataGossip;
2
3
4
5
6
7
8
9
10
11
# 故障检测
Redis 集群故障检测用于识别大多数节点何时不再可访问主节点或副本节点,然后通过将副本提升为主节点来响应。当无法进行副本提升时,集群将处于错误状态以停止接收来自客户端的查询。
如前所述,每个节点有flags字段,是一个 bit 数组,标识着节点状态。有两个标志用于故障检测,称为 PFAIL 和 FAIL。 PFAIL 表示可能的故障,是一种未确认的故障类型。 FAIL 表示节点出现故障,并且大多数主节点在固定时间内确认了此情况。
# PFAIL 标志
possible failed ,可能是失败了,就是说一个节点认为另一个节点是挂了。
Redis 集群节点不可访问的概念是,我们有一个活动 ping(我们发送的 ping,我们尚未收到回复)等待超过 NODE_TIMEOUT 的时间。
# FAIL 标志
仅 PFAIL 标志只是每个节点拥有的关于其他节点的本地信息,但不足以触发副本提升。对于要考虑关闭的节点,需要将 PFAIL 条件升级为 FAIL 条件。
当满足以下一组条件时,PFAIL 条件升级为 FAIL 条件:(具体代码:cluster.c#markNodeAsFailingIfNeeded)
- 某个节点(我们将其称为 A)有另一个节点 B 标记为 PFAIL。
- 节点 A 通过 gossip 部分从集群中大多数 master 的角度收集有关 B 状态的信息。
- 超过一半的节点在
NODE_TIMEOUT * FAIL_REPORT_VALIDITY_MULT时间内发出 PFAIL 或 FAIL 状态信号。(在当前实现中,有效性因子设置为 2,因此这只是 NODE_TIMEOUT 时间的两倍)。
FAIL 消息将强制每个接收节点将节点标记为 FAIL 状态,无论它是否已经将节点标记为 PFAIL 状态。
注意,一个节点只可以从 PFAIL 到 FAIL,但在以下情况下可以清除 FAIL 标志:(具体代码:cluster.c#clearNodeFailureIfNeeded)
- 该节点已经可以访问并且是一个副本。在这种情况下,可以清除 FAIL 标志,因为副本未进行故障转移。
- 该节点已经是可访问的,并且是一个不为任何插槽提供服务的主节点。在这种情况下,可以清除 FAIL 标志,因为没有插槽的 master 并没有真正参与集群,并且正在等待配置以加入集群。
- 该节点已经可以访问并且是一个主节点,但是很长一段时间(N 倍 NODE_TIMEOUT)已经过去,则会清除 FAIL 状态。
# 配置处理、传播和故障转移
# 集群当前版本
Redis Cluster 使用了一个类似于 Raft 算法中 "term" 的概念。在 Redis 集群中,该术语被称为 epoch,它用于为事件提供增量版本控制。当多个节点提供相互冲突的信息时,另一个节点就有可能了解哪个状态是最新的。
是currentEpoch一个 64 位无符号数。
在创建节点时,每个 Redis Cluster 节点(包括副本节点和主节点)都将其设置currentEpoch为 0。
每次从另一个节点接收到一个数据包时,如果发送者的版本(集群总线消息头的一部分)大于本地节点版本,currentEpoch则更新为发送者纪元。
由于这些语义,最终所有节点都会同意 currentEpoch 集群中的最大节点。
当集群的状态发生变化并且节点寻求协议以执行某些操作时,将使用此信息。
目前,这仅在副本提升期间发生,如下一节所述。基本上,版本是集群的逻辑时钟,它指示给定的信息胜过具有较小版本的信息。
# 配置的版本
每个主机总是configEpoch在 ping 和 pong 数据包中通告它,以及一张通告它所服务的插槽集的位图。
configEpoch创建新节点时,在 master 中将其设置为零。
configEpoch在副本选举期间创建一个新的。试图替换失败的主节点的副本会增加它们的epoch并尝试从大多数主节点那里获得授权。当一个副本被授权时,configEpoch 会创建一个新的唯一且副本使用新的configEpoch.
configEpoch当不同的节点声称不同的配置(由于网络分区和节点故障而可能发生的情况)时,这有助于解决冲突。
副本节点也在configEpochping 和 pong 数据包中通告该字段,但在副本的情况下,该字段表示configEpoch其最后一次交换数据包时的主节点。这允许其他实例检测副本何时具有需要更新的旧配置(主节点不会向具有旧配置的副本授予投票)。
每次configEpoch对某个已知节点进行更改时,所有接收到此信息的节点都会将其永久存储在 nodes.conf 文件中。同样的情况也发生在currentEpoch值上。fsync-ed在节点继续其操作之前更新时,保证这两个变量被保存并保存到磁盘。
在故障转移期间使用简单算法生成的configEpoch值保证是新的、增量的和唯一的。
# configEpoch 冲突解决算法
下面两个跳过共识修改 configEpoch 的两个操作比较危险,最好确定一个成功后再执行另一个:
CLUSTER_FAILOVER TAKEOVER(手动Failover)直接将一个Slave提升为Master,不需要大多数Master同意。Slot Migration同样不需要大多数Master同意。
所以就有可能出现同一个Slot有两个相同ConfigEpoch的Master宣称由自己负责,这种冲突的解决算法是:
- 如果Master A发现Master B也宣称了对Slot X的主权,并且两者的ConfigEpoch一样
- 如果Master A的NodeID的字典顺比Master B的小
- 那么Master A就把己侧的 currentEpoch+1,同时ConfigEpoch改成和CurrentEpoch一样
# 哈希槽配置传播
Slave赢得选举之后会在己侧更新Slots上的归属信息,然后在定时的PING/PONG中将这个信息传播出去。
PING/PONG总是会携带上Slots所属Master的信息(包括ConfigEpoch)
PING的Reciever如果发现Sender的某个Slot上的Master.ConfigEpoch比自己这里记录的小,那么就会返回UPDATE告诉Sender更新Slots归属信息。
下面是两个规则:
- 如果一个Slot不属于任何Master,然后有一个Master宣称拥有它,那么就修改己侧的Slots信息把这个Slot关联到这个Master上。
- 如果一个Slot已经归属一个Master,然后又有一个Master宣称拥有它,那么就看谁的ConfigEpoch大,大的那个赢
# 副本迁移算法
Slave迁移时一个自动过程。
举个例子,现在有Master A、B,它们对应的Slave有A1、B1、B2。现在A死了,A1顶替上去,不过这个时候A1就是一个光棍Master(它没有Slave),B有富余的Slave(B1和B2),把其中一个匀给A1当Slave。
这个过程不需要共识,因为只是修改Slave的归属,也不会修改ConfigEpoch。
Slave迁移有两个规则:
- 当有多个Slave富余时,选择NodeID字典顺最小的那个来迁移
- 只有当Master的Slave数量>=
cluster-migration-barrier时,才会挑选它的Slave做Migration
# 发布订阅
在集群模式下,所有的publish命令都会向所有节点(包括从节点)进行广播,造成每条publish数据都会在集群内所有节点传播一次,加重了带宽负担,对于在有大量节点的集群中频繁使用pub,会严重消耗带宽,不建议使用。
在 Redis 7.0 提供了 ssubscribe 命令解决了这个问题。