 一致性哈希算法
一致性哈希算法
# 简介
常见的负载均衡方法有很多,但是它们的优缺点也都很明显:
- 随机访问策略。系统随机访问,缺点:可能造成服务器负载压力不均衡,俗话讲就是撑的撑死,饿的饿死。
- 轮询策略。请求均匀分配,如果服务器有性能差异,则无法实现性能好的服务器能够多承担一部分。
- 权重轮询策略。权值需要静态配置,无法自动调节,不适合对长连接和命中率有要求的场景。
- Hash取模策略。不稳定,如果列表中某台服务器宕机,则会导致路由算法产生变化,由此导致命中率的急剧下降。
- 一致性哈希策略。
以上几个策略,排除本篇介绍的一致性哈希,可能使用最多的就是 Hash取模策略了。Hash取模策略的缺点也是很明显的,这种缺点也许在负载均衡的时候不是很明显,但是在涉及数据访问的主从备份和分库分表中就体现明显了。
# 一致性Hash性质
考虑到分布式系统每个节点都有可能失效,并且新的节点很可能动态的增加进来,如何保证当系统的节点数目发生变化时仍然能够对外提供良好的服务,这是值得考虑的,尤其实在设计分布式缓存系统时,如果某台服务器失效,对于整个系统来说如果不采用合适的算法来保证一致性,那么缓存于系统中的所有数据都可能会失效(即由于系统节点数目变少,客户端在请求某一对象时需要重新计算其hash值(通常与系统中的节点数目有关),由于hash值已经改变,所以很可能找不到保存该对象的服务器节点),因此一致性hash就显得至关重要,良好的分布式cahce系统中的一致性hash算法应该满足以下几个方面:
# 平衡性(Balance)
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
# 单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。简单的哈希算法往往不能满足单调性的要求,如最简单的线性哈希:x = (ax + b) mod (P),在上式中,P表示全部缓冲的大小。不难看出,当缓冲大小发生变化时(从P1到P2),原来所有的哈希结果均会发生变化,从而不满足单调性的要求。哈希结果的变化意味着当缓冲空间发生变化时,所有的映射关系需要在系统内全部更新。而在P2P系统内,缓冲的变化等价于Peer加入或退出系统,这一情况在P2P系统中会频繁发生,因此会带来极大计算和传输负荷。单调性就是要求哈希算法能够应对这种情况。
# 分散性(Spread)
在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
# 负载(Load)
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
# 平滑性(Smoothness)
平滑性是指缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的。
# 算法思想
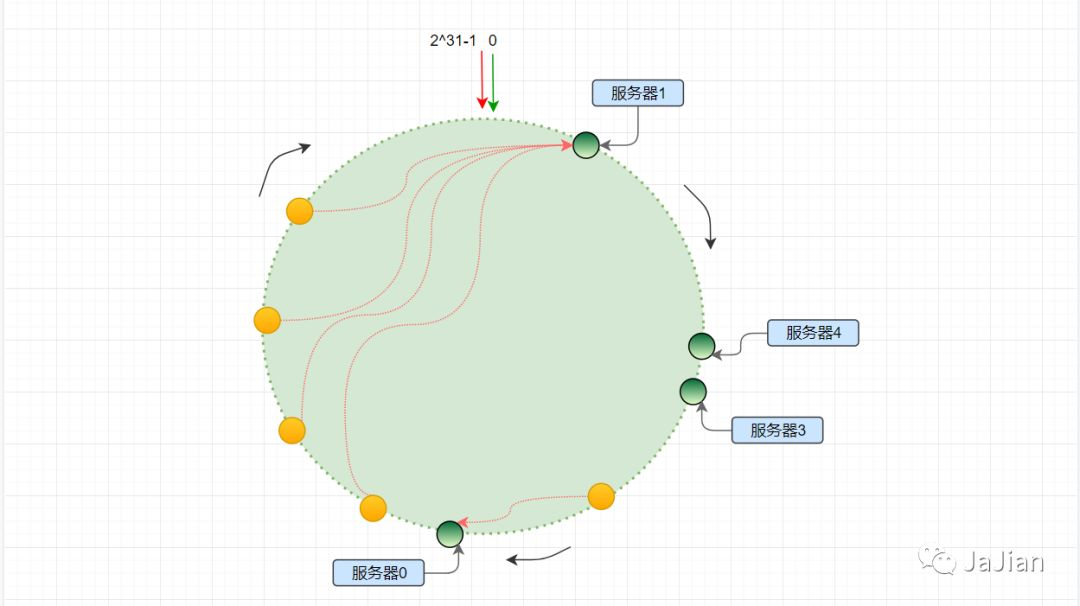
- 首先求出memcached服务器(节点)的哈希值,并将其配置到0~23^2的圆上。
- 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过23^2仍然找不到服务器,就会保存到第一台服务器上。
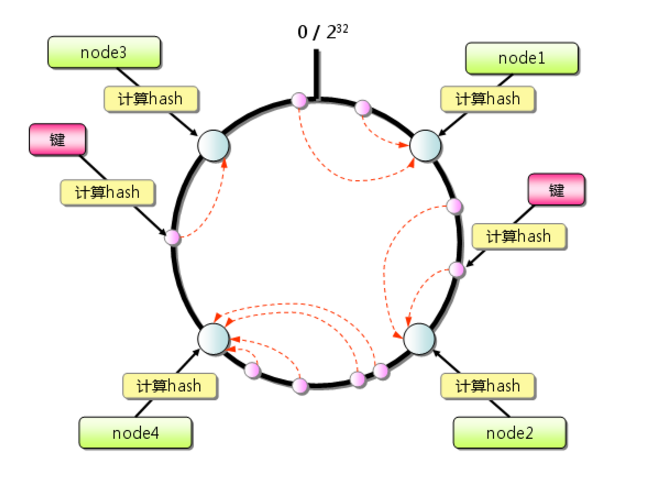
当我们添加一台机器的时候,只会将一部分节点分配到新加入的节点,如图所示,Node2-Node5之间的数据应该是存储在Node3上,加上新节点Node5之后,只需要将Node2-Node5之间的数据从Node3重分布到Node5就行了,不会全部重分布。
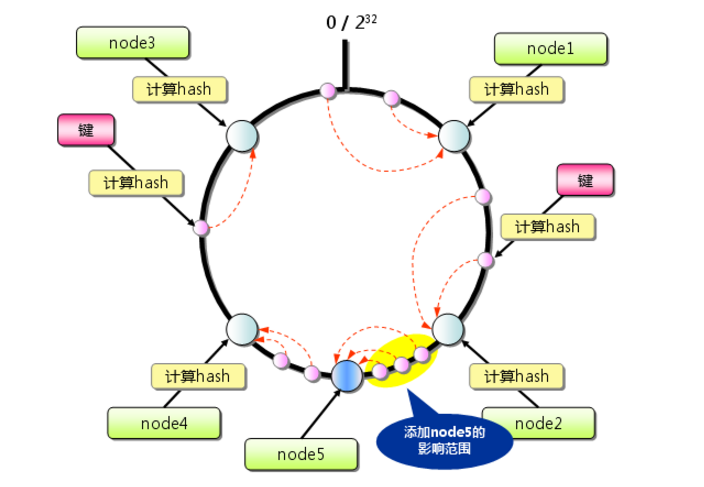
不过这个有一个问题,就是数据分布的不均匀了。
# 虚拟节点
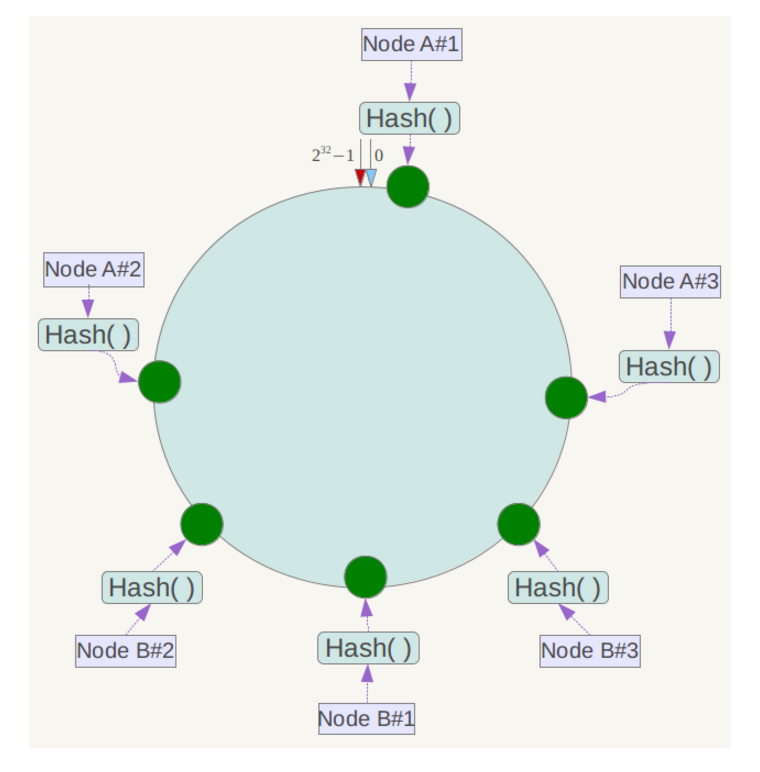
为了解决节点过少数据分部不均匀的问题,引入了虚拟节点,增加hash分布的均匀性。hash环上不再存在物理节点,而是存虚拟节点,虚拟节点对应对应的物理机器。
# 总结
一致性哈希解决了数据迁移的时候全量重新分布的问题,只用重新分布一部分。还有就是哈希冲突问题还是会有的,但是冲突的概率很低,而且就算冲突了也影响不大。