 集群模式
集群模式
# 概念
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存。Redis-Cluster 提供了以下能力:
- 某个节点不能与其他节点通讯或者挂掉时,整个集群依旧可以继续服务的能力。
- 在多个节点之间自动分片存储的能力。
# 数据切片
Redis Cluster 没有使用一致性哈希,而是使用一种不同形式的分片,其中每个键在概念上都是我们所谓的哈希槽(hash solt)的一部分。 Redis 集群中有 16384 个哈希槽,要计算给定键的哈希槽,将键的以 CRC16 (循环校验码) 然后用 16384 取模即可得到所在的槽。 Redis 集群中的每个节点都负责哈希槽的子集,因此,例如一个具有 3 个节点的集群,其中:
- 节点 A 包含从 0 到 5500 的哈希槽。
- 节点 B 包含从 5501 到 11000 的哈希槽。
- 节点 C 包含从 11001 到 16383 的哈希槽。
这使得添加和删除集群节点变得容易。例如
- 如果想添加一个新节点 D,需要将节点 A、B、C 的一些哈希槽移动到 D。
- 同样,如果想从集群中删除节点 A,只需要把 A 的哈希槽移动到 B 和 C 即可,一旦节点 A 为空,则可以把它完全从集群中删除。
将哈希槽从一个节点移动到另一个节点不需要停止任何操作;因此,添加和删除节点,或更改节点持有的哈希槽的百分比,不需要停机。
只要单个命令执行(或整个事务,或 Lua 脚本执行)涉及的所有键都属于同一个哈希槽,Redis Cluster 就支持多个键操作。用户可以通过使用哈希标签的功能强制多个键成为同一个哈希槽的一部分。
# 哈希标签
哈希标签(Hash tags)定义在 Redis Cluster 规范中,但要点是如果键中的 {} 括号之间有子字符串,则仅对字符串内的内容进行哈希处理。例如,密钥 user:{123}:profile 和 user:{123}:account 保证位于相同的哈希槽中,因为它们共享相同的哈希标记。因此,您可以在同一个多键操作中对这两个键进行操作。
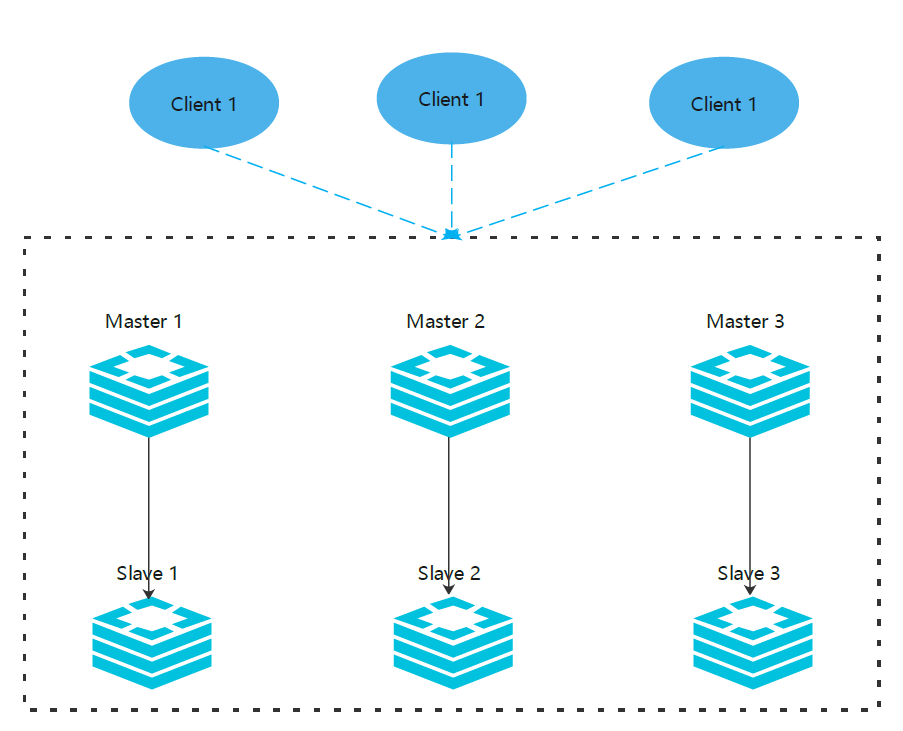
# 集群中的主从模式
为了保证某个节点挂了或者没有办法和其他节点通讯时集群服务依旧可用,Redis 集群使用主从模式。 在我们的具有节点 A、B、C 的示例集群中,如果节点 B 发生故障,集群将无法继续,因为我们不再有方法为 5501-11000 范围内的哈希槽提供服务。 但是,在创建集群时(或之后),我们为每个 master 添加一个从节点,这样最终的集群由作为 master 节点的 A、B、C 和作为主节点的从节点 A1、B1、C1 组成。这样,如果节点 B 发生故障,系统可以继续运行。
节点 B1 复制 B,而 B 发生故障,集群会将节点 B1 提升为新的 master,并继续正常运行。 但是要注意,如果节点 B 和 B1 同时出现故障,Redis Cluster 将无法继续运行。
# Cluster 相关配置
- cluster-enabled
<yes/no>:开启集群支持。 - cluster-config-file
<filename>:集群配置的文件,自动生成的,记录集群状态的,下次启动时自动加载,集群信息变更时自动刷新。 - cluster-node-timeout
<milliseconds>: Redis 集群节点在不被视为失败的情况下不可用的最长时间。如果主节点在超过指定的时间内无法访问,它将由其副本进行故障转移。值得注意的是,在指定时间内无法到达大多数主节点的每个节点都将停止接受查询。 - cluster-slave-validity-factor
<factor>:如果设置为 0,节点将始终认为自己有效,无论主节点与从节点断开了多久,都会尝试进行故障转移。如果不是 0 ,假设cluster-node-timeout为 5秒,且 cluster-slave-validity-factor 为 10,那么故障转移的超时时间为 50 秒,超过后就认为自己的网络也出问题了,不再尝试故障转义。所以如果设置一个非 0 值可能会导致集群再故障后不可用,必须要手动加回集群才能恢复服务。 - cluster-migration-barrier
<count>: 一个主节点将保持连接的最小副本数,以便另一个副本迁移到不再被任何副本覆盖的主节点。 - cluster-require-full-coverage
<yes/no>: 如果设置为 yes(默认),如果某个键计算出的插槽没有被覆盖,集群将停止接受写入。如果该选项设置为 no,集群仍将提供现有的插槽 key 的查询服务。 - cluster-allow-reads-when-down
<yes/no>: 设置为 yes 后集群标识失败后依旧可以提供查询服务器。yes 保证可用性,no 保证一致性。
# 搭建 Redis 集群
redis 官方推荐至少 3 主节点 3 从节点来搭建集群环境。
# 配置文件
复制 6 份 redis-7001.conf ,端口号从 7001 - 7006。
port 7001
pidfile "/var/run/redis_7001.pid"
# 开启redis的集群模式
cluster-enabled yes
# 配置集群模式下的配置文件名称和位置,redis-cluster.conf这个文件是集群启动后自动生成的,不需要手动配置。
cluster-config-file redis-cluster-7001.conf
# 默认是 port + 10000 , 可以通过下面的命令指定
cluster-port 8001
2
3
4
5
6
7
8
# 启动集群
redis-server redis-7001.conf
redis-server redis-7002.conf
.......
2
3
然后可以看到下面的输出的日志,看到实例的 ID,这个 ID 是永远不会变的了。
17371:M 22 Jul 2022 20:14:37.714 * No cluster configuration found, I'm 608d3705970408b091358edc536c62bae59f6cf4
# 创建集群
3 主 3 从。
redis-cli --cluster create 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006 --cluster-replicas 1
最终可以看到分配哈希槽的信息,并且输出 yes 后不出意外可以看到
[OK] All 16384 slots covered
# 测试集群
通过 redis-cli -c 的方式连接即可。
$ redis-cli -c -p 7001
redis 127.0.0.1:7000> set foo bar
-> Redirected to slot [12182] located at 127.0.0.1:7002
OK
redis 127.0.0.1:7003> set hello world
-> Redirected to slot [866] located at 127.0.0.1:7000
OK
redis 127.0.0.1:7001> get foo
-> Redirected to slot [12182] located at 127.0.0.1:7002
"bar"
redis 127.0.0.1:7003> get hello
-> Redirected to slot [866] located at 127.0.0.1:7000
"world"
2
3
4
5
6
7
8
9
10
11
12
13
redis-cli 对集群的支持是非常基础, 它总是依靠 Redis 集群节点来将它转向(redirect)至正确的节点。
一个真正的集群客户端应该做得比这更好: 它应该用缓存记录起哈希槽与节点地址之间的映射(map), 从而直接将命令发送到正确的节点上面。
这种映射只会在集群的配置出现某些修改时变化, 比如说, 在一次故障转移(failover)之后, 或者系统管理员通过添加节点或移除节点来修改了集群的布局(layout)之后, 诸如此类。
# 代码测试
通过一个 Java 程序来测试一下我们的集群,这里用 jedis 来测试。
package com.unclezs.redis.cluster;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import java.util.HashSet;
import java.util.Set;
/**
* @author blog.unclezs.com
* @since 2022/7/24 2:32 PM
*/
public class RedisClusters {
public static void main(String[] args) throws InterruptedException {
Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7001));
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7002));
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7003));
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7004));
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7005));
jedisClusterNode.add(new HostAndPort("127.0.0.1", 7006));
try (JedisCluster jedisCluster = new JedisCluster(jedisClusterNode);) {
String last = jedisCluster.get("__last__");
int index = 0;
if (last != null) {
index = Integer.parseInt(last);
}
for (int i = index; i < Integer.MAX_VALUE; i++) {
jedisCluster.set("name" + i, String.valueOf(i));
System.out.println(jedisCluster.get("name" + i));
jedisCluster.set("__last__", String.valueOf(i));
Thread.sleep(1000L);
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
主要内容就是每秒钟往 redis 里面写入一个值。然后可以在 redis 上面看到被写入了不通的哈希槽。
# 重新分片
重新分配哈希槽,并且是不间断停机的重新分。可以把上面的测试程序跑着来测试,可以把 sleep 干掉,然负载更符合实际一点。
# 交互方式重新分片
随便指定集群中的一个节点就可以,自动发现其他节点。
redis-cli --cluster reshard 127.0.0.1:7001
执行后会让你输出你要移动多少个哈希槽到某个节点,比如 5 个
How many slots do you want to move (from 1 to 16384)?
输出 5 回车,然后回提示让你输出要移动到哪个节点,输出 nodeId,可以通过下面的命令查看节点信息。
redis-cli -p 7000 cluster nodes | grep myself
--------
97a3a64667477371c4479320d683e4c8db5858b1 :0 myself,master - 0 0 0 connected 0-5460
2
3
4
然后会让你输出要从哪些节点移动哈希槽,可以输出 nodeId,全部输入完成后输入 done 就行。或者输入 all 从所有节点中移动。
最后就会重新分配哈希槽了,通过下面的命令可以查看哈希槽信息。
redis-cli --cluster check 127.0.0.1:7001
# 交互模式
cluster slots
2
3
4
# 一键重新分配
redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
# 例子
redis-cli --cluster reshard 127.0.0.1:7001 --cluster-from all --cluster-to 1b09694a6d5c151479086c13a60636614121666e --cluster-slots 5 --cluster-yes
2
3
4
其中 --cluster-yes 会跳过交互默认 yes,也可以通过环境变量 REDISCLI_CLUSTER_YES 实现一样的效果。
# 故障迁移测试
# 自动故障迁移
下线 7002 的节点,然后查看集群信息
redis-cli -p 7001 cluster nodes
-------------
7a8c6effe2f901163af3215a9cc14d202a7adf7a 127.0.0.1:7006@17006 slave dfb854284143d158bedc1cbf797b12433e650c70 0 1658664577665 3 connected
9ad92eeb0d29e2366b6374176214d2c06b82ba23 127.0.0.1:7002@17002 master,fail - 1658664544331 1658664541000 2 disconnected
a973a2e50bdaecd901928fd627ab377df31e19d5 127.0.0.1:7004@17004 slave 1b09694a6d5c151479086c13a60636614121666e 0 1658664576659 7 connected
1b09694a6d5c151479086c13a60636614121666e 127.0.0.1:7001@17001 myself,master - 0 1658664578000 7 connected 0-5466 10923-10926
917d27469a8aafbc7e11ca8ceadfe911d67664e5 127.0.0.1:7005@17005 master - 0 1658664578673 8 connected 5467-10922
dfb854284143d158bedc1cbf797b12433e650c70 127.0.0.1:7003@17003 master - 0 1658664575648 3 connected 10927-16383
2
3
4
5
6
7
8
9
可以看到,7002 标记为 fail 了,然后从节点 7005 顶替了他的位置,字段信息如下:
然后将 7002 重启,会发现 7002 节点变成了从节点,7005 依旧为主节点。
# 手动故障迁移
手动故障迁移比自动故障迁移更加安全,因为不会丢失数据。在从节点 7002 执行下面命令:
cluster failover
因为 7002 在上面自动故障迁移测试的时候已经变为从节点了,``7005变为了主节点,现在执行这个命令将会把7002`从新变为主节点。
# 节点操作
# 添加空的主节点
后面的 7001 节点是随便指定的,只要是机器里面的一个节点即可。
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001
# 添加从节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 --cluster-slave
# 添加指定主节点的从节点
redis-cli --cluster add-node 127.0.0.1:7007 127.0.0.1:7001 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
# 切换主节点
nodeId 为主节点 Id,在从节点中执行。
cluster replicate 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
# 删除节点
7001 还是集群内的节点之一即可, nodeId 为要删除的节点 ID。
redis-cli --cluster del-node 127.0.0.1:7001 `<node-id>`
# 例子
redis-cli --cluster del-node 127.0.0.1:7001 cc33797c2f9f58b20bdca2550933fb7b2eb4a955
2
3
4
# 一些思考
# 为什么哈希槽使用 16384 个?
作者原回答可见:why redis-cluster use 16384 slots? (opens new window)
redis cluster使用下面算法计算槽位
slot = CRC16(key) & 16384
hash 函数 crc16() 产生的 hash 值有 16 位,自然会产生 2^16 = 65536 个值。也就是 hash 的值分布在 0-65535 范围内,按道理我们应该使用 65536 来进行 mod 操作,为何使用16384呢?
- 消息大小的考虑,槽位数越大,维护槽位信息占用空间越大,浪费带宽,也容易导致网络拥塞。
我们知道集群也是会互相通讯的,通讯时会携带节点信息,redis 定义的信息结构如下:
#define CLUSTER_SLOTS 16384
typedef struct {
char sig[4]; /* Signature "RCmb" (Redis Cluster message bus). */
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 1. */
uint16_t port; /* TCP base port number. */
uint16_t type; /* Message type */
uint16_t count; /* Only used for some kind of messages. */
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
unsigned char myslots[CLUSTER_SLOTS/8];
char slaveof[CLUSTER_NAMELEN];
char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */
char notused1[34]; /* 34 bytes reserved for future usage. */
uint16_t cport; /* Sender TCP cluster bus port */
uint16_t flags; /* Sender node flags */
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data;
} clusterMsg;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
其中的 unsigned char myslots[CLUSTER_SLOTS/8]; 维护了当前节点持有槽信息的 bitmap。每一位代表一个槽,对应位为 1 表示此槽属于当前节点。因为#define CLUSTER_SLOTS 16384 故而myslots占用空间为: 16384/8/1024=2kb ,但如果 #define CLUSTER_SLOTS 为 65536,则占用了 8kb。
而且在消息体中也会携带其他节点的信息用于交换。这个“其他节点的信息”具体约为集群节点数量的1/10,至少携带3个节点的信息。故而集群节点越多,消息内容占用空间就越大。
- redis集群的主节点数据一般不可能超过1000个。
节点越多,交换信息报文也越大;另一方面因为节点槽位信息是通过 bitmap 维护的,传输过程中会对 bitmap 进行压缩。如果槽位越小,节点也少的情况下,bitmap的填充率 slots/N (N表示节点数)就较小,对应压缩率就高。反之节点很少槽位很多则压缩率就很低。
所以综合考虑,作者觉得实际上16384个槽位就够了。