 操作系统之内存管理
操作系统之内存管理
# 内存管理的概念
操作系统作为系统资源的管理者,当然也需要对内存进行管理,要管些什么呢?
- 操作系统负责内存空间的分配与回收。
- 操作系统需要提供某种技术从逻辑.上对内存空间进行扩充。
- 操作系统需要提供地址转换功能,负责程序的逻辑地址与物理地址的转换。
- 操作系统需要提供内存保护功能。保证各进程在各自存储空间内运行,互不干扰
# 逻辑(虚拟)地址和物理地址
我们编程⼀般只有可能和逻辑地址打交道,⽐如在 C 语⾔中,指针⾥⾯存储的数值就可以理解成为内存⾥的⼀个地址,这个地址也就是我们说的逻辑地址,逻辑地址由操作系统决定。物理地址指的是真实物理内存中地址,更具体⼀点来说就是内存地址寄存器中的地址。物理地址是内存单元真正的地址。
# 连续分配的块式管理
远古时代的计算机操系统的内存管理⽅式。将内存分为⼏个固定⼤⼩的块,每个块中只包含⼀个进程。如果程序运⾏需要内存的话,操作系统就分配给它⼀块,如果程序运⾏只需要很⼩的空间的话,分配的这块内存很⼤⼀部分⼏乎被浪费了。这些在每个块中未被利⽤的空 间,我们称之为碎⽚。
连续分配内存有一下几种算法
| 算法 | 算法思想 | 分区排列顺序 | 优点 | 缺点 |
|---|---|---|---|---|
| 首次适应 | 从头到尾找适合的分区 | 空闲分区以地址递增次序排列 | 综合看性能最好。算法开销小,回收分区后一般不需要对空闲分区队列重新排序 | |
| 最佳适应 | 优先使用更小的分区,以保留更多大分区 | 空闲分区以容量递增次序排列 | 会有更多的大分区被保留下来,更能满足大进程需求 | 会产生很多太小的、难以利用的碎片;算法开销大,回收分区后可能需要对空闲分区队列重新排序 |
| 最坏适应 | 优先使用更大的分区,以防止产生太小的不可用的碎片 | 空闲分区以容量递减次序排列 | 可以减少难以利用的小碎片 | 大分区容易被用完,不利于大进程;算法开销大(原因同上) |
| 邻近适应 | 由首次适应演变而来,每次从上次查找结束位置开始查找 | 空闲分区以地址递增次序排列(可排列成循环链表) | 不用每次都从低地址的小分区开始检索。算法开销小(原因同首次适应算法) | 会使高地址的大分区也被用完 |
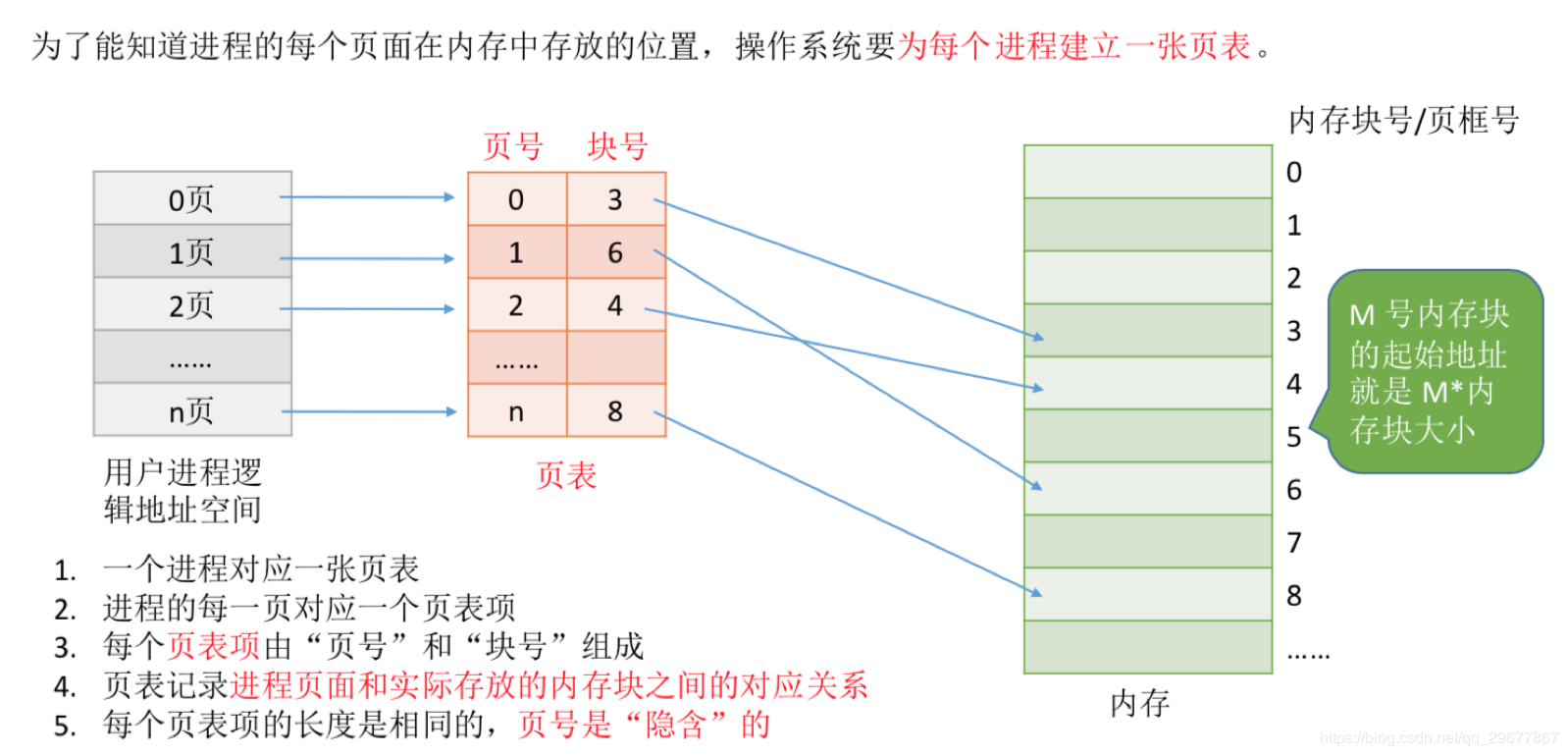
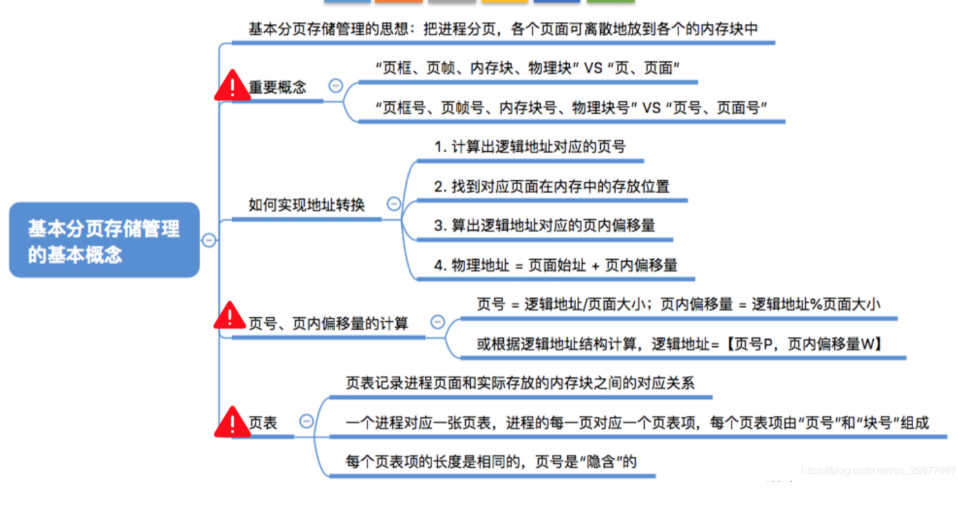
# ⻚式管理
如果允许将一个进程分散到许多不连续的空间,就可以避免内存紧缩,减少碎片。基于这一思想,通过引入进程的逻辑地址,把进程地址空间与实际存储空间分离,增加存储管理的灵活性。
把主存分为⼤⼩相等且固定的⼀⻚⼀⻚的形式,⻚较⼩,相对相⽐于块式管理的划分⼒度更⼤,提⾼了内存利⽤率,减少了碎⽚。⻚式管理通过⻚表对应逻辑地址和物理地址。
# 页表
# 快表和多级⻚表
⻚表管理机制中有两个很重要的概念:快表和多级⻚表,这两个东⻄分别解决了⻚表管理中很重要的两个问题。
- 虚拟地址到物理地址的转换要快。
- 解决虚拟地址空间⼤,⻚表也会很⼤的问题。
# 快表
为了解决虚拟地址到物理地址的转换速度,操作系统在⻚表⽅案基础之上引⼊了快表来加速虚拟地址到物理地址的转换。我们可以把块表理解为⼀种特殊的⾼速缓冲存储器(Cache),其中的内容是⻚表的⼀部分或者全部内容。作为⻚表的 Cache,它的作⽤与⻚表相似,但是提⾼了访问速率。由于采⽤⻚表做地址转换,读写内存数据时 CPU 要访问两次主存。有了快表,有时只要访问⼀次⾼速缓冲存储 器,⼀次主存,这样可加速查找并提⾼指令执⾏速度。
使⽤快表之后的地址转换流程是这样的:
- 根据虚拟地址中的⻚号查快表;
- 如果该⻚在快表中,直接从快表中读取相应的物理地址;
- 如果该⻚不在快表中,就访问内存中的⻚表,再从⻚表中得到物理地址,同时将⻚表中的该映射表项添加到快表中;
- 当快表填满后,⼜要登记新⻚时,就按照⼀定的淘汰策略淘汰掉快表中的⼀个⻚。
看完了之后你会发现快表和我们平时经常在我们开发的系统使⽤的缓存(⽐如 Redis)很像,的确是这样的,操作系统中的很多思想、很多经典的算法,你都可以在我们⽇常开发使⽤的各种⼯具或者框架中找到它们的影⼦。
# 多级⻚表
引⼊多级⻚表的主要⽬的是为了避免把全部⻚表⼀直放在内存中占⽤过多空间,特别是那些根本就不需要的⻚表就不需要保留在内存中。多,多级⻚表属于时间换空间的典型场景。
推荐阅读 多级页表如何节约内存 (opens new window)
# 总结
为了提⾼内存的空间性能,提出了多级⻚表的概念;但是提到空间性能是以浪费时间性能为基础的,因此为了补充损失的时间性能,提出了快表(即 TLB)的概念。 不论是快表还是多级⻚表实际上都利⽤到了程序的局部性原理。
# 段式管理
⻚式管理虽然提⾼了内存利⽤率,但是⻚式管理其中的⻚实际并⽆任何实际意义。段式管理把主存分为⼀段段的,每⼀段的空间⼜要⽐⼀⻚的空间⼩很多 。但是,最重要的是段是有实际意义的,每个段定义了⼀组逻辑信息,例如,有主程序段 MAIN、⼦程序段 X、数据段 D及栈段 S 等。 段式管理通过段表对应逻辑地址和物理地址。
# 分⻚机制和分段机制的共同点和区别
共同点:
- 分⻚机制和分段机制都是为了提⾼内存利⽤率,较少内存碎⽚。
- ⻚和段都是离散存储的,所以两者都是离散分配内存的⽅式。但是,每个⻚和段中的内存是连续的。
不同点:
- ⻚的⼤⼩是固定的,由操作系统决定;⽽段的⼤⼩不固定,取决于我们当前运⾏的程序。
- 分⻚仅仅是为了满⾜操作系统内存管理的需求,⽽段是逻辑信息的单位,在程序中可以体现为代码段,数据段,能够更好满⾜⽤户的需要。
# 段⻚式管理
段⻚式管理机制结合了段式管理和⻚式管理的优点。简单来说段⻚式管理机制就是把主存先分成若⼲段,每个段⼜分成若⼲⻚,也就是说 段⻚式管理机制中段与段之间以及段的内部的都是离散的。