数据类型详解
数据类型详解
# Strings
# 介绍
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
set key sth
# 底层
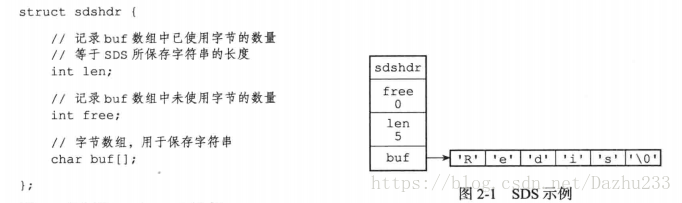
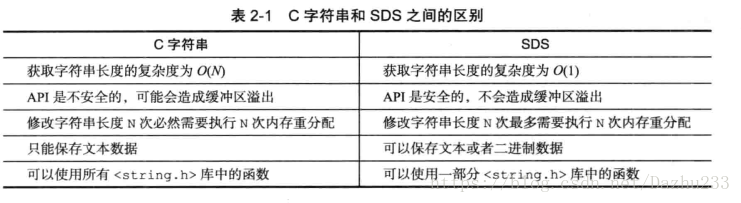
Redis中为了实现方便的扩展、安全和性能,自己定义了一个结构用来存储字符串。 我们叫它SDS(simple dynamic string)
推荐阅读 Redis底层之String (opens new window)
# Hashes
# 介绍
这个是类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 hash 里的某个字段。
hset person name bingo
hset person age 20
hset person id 1
hget person name
person = {
"name": "bingo",
"age": 20,
"id": 1
}
2
3
4
5
6
7
8
9
10
# 底层
# 源码
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表数组的大小
unsigned long sizemask; // 用于映射位置的掩码,值永远等于(size-1)
unsigned long used; // 哈希表已有节点的数量
} dictht;
typedef struct dictEntry {
void *key; // 键
union { // 值
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,形成单向链表
} dictEntry;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
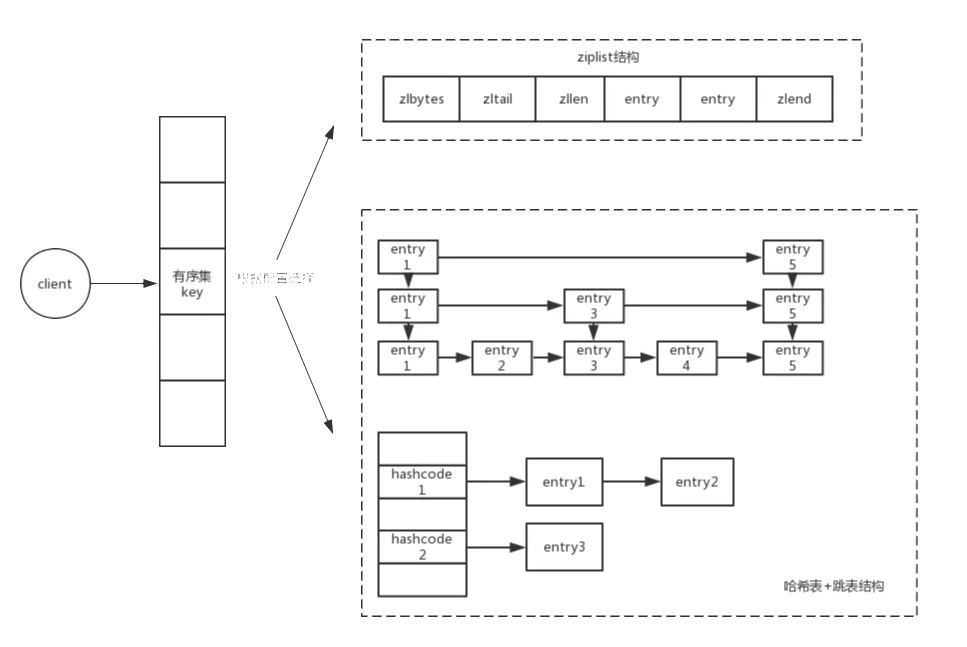
总体结构图
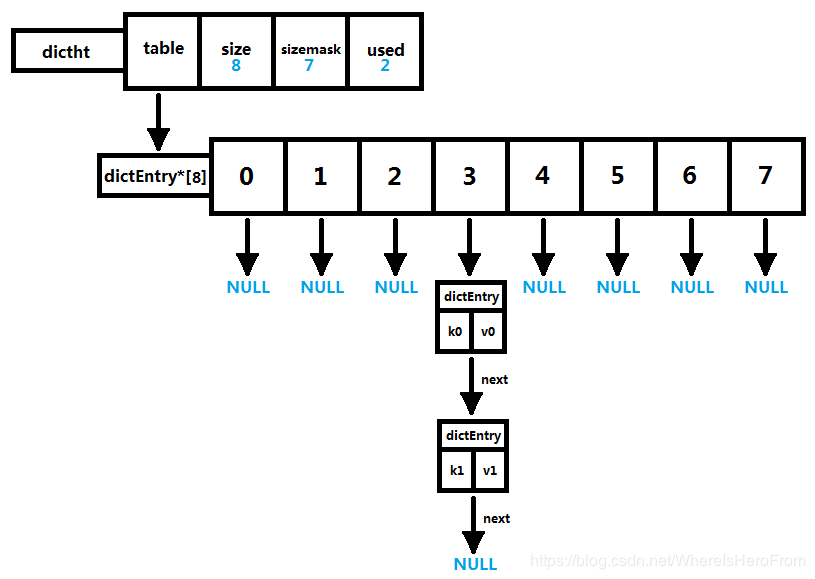
是不是很眼熟,就是Java的HashMap一样的,使用的拉链法解决冲突。
# 补充
hash类型是一个dict,一个dict有两张hash表,其中一张表是用来做rehash的
与Java的HashMap不同的是:
- Redis的字典只能是字符串,
- rehash的方式不一样:Java是一次性rehash全部;Redis为了追求高性能,不能堵塞服务,所以采用了渐进式rehash策略。
# Lists
# 介绍
Lists 是有序列表,这个可以玩儿出很多花样。
比如可以通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 list 实现分页查询,这个是很棒的一个功能,基于 Redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
# 0开始位置,-1结束位置,结束位置为-1时,表示列表的最后一个位置,即查看所有。
lrange mylist 0 -1
#比如可以搞个简单的消息队列,从 list 头怼进去,从 list 尾巴那里弄出来。
lpush mylist 1
lpush mylist 2
lpush mylist 3 4 5
# 1
rpop mylist
2
3
4
5
6
7
8
9
10
# 底层
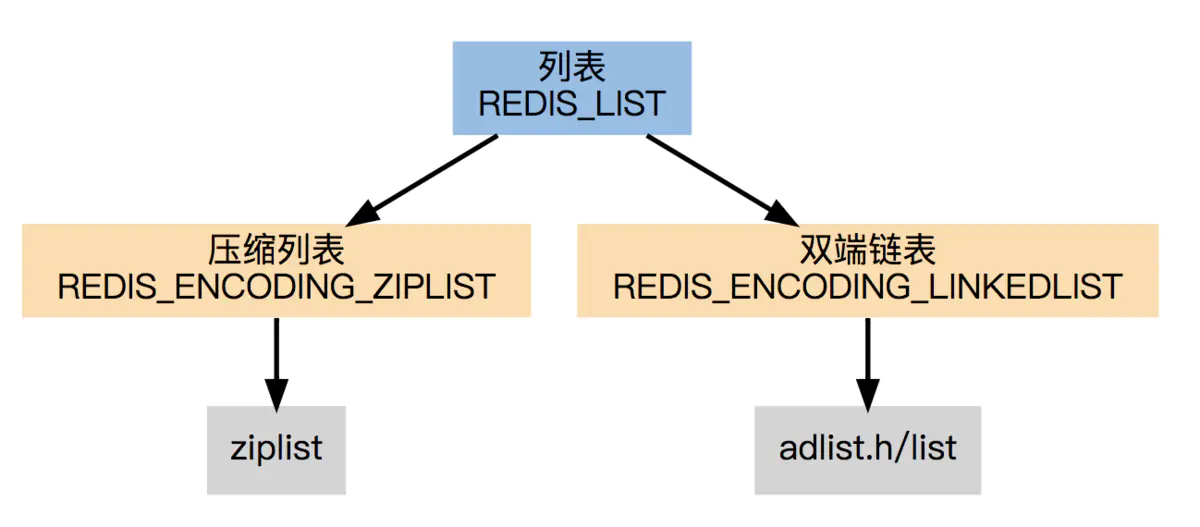
# 3.2版本之前
3.2版本之前的 使用压缩列表(zipList)和双向链表(linkedlist)
初始为zipList,当链表entry数据超过512、或单个value 长度超过64,底层就会转化成linkedlist编码
优缺点:
双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。 ziplist存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝。
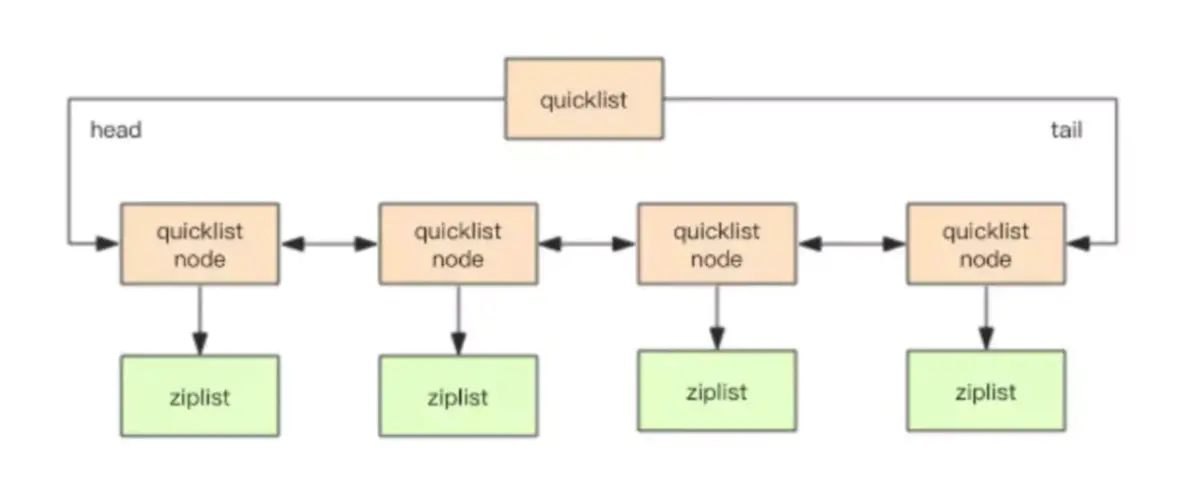
# 3.2版本之后
使用quickList实现。可以认为quickList,是ziplist和linkedlist二者的结合;quickList将二者的优点结合起来。
quickList是一个ziplist组成的双向链表。每个节点使用ziplist来保存数据。 本质上来说,quicklist里面保存着一个一个小的ziplist。结构如下:
推荐阅读 Redis列表list底层原理 (opens new window)
# Sets
# 介绍
Sets 是无序集合,自动去重。
直接基于 set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 jvm 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于 Redis 进行全局的 set 去重。
可以基于 set 玩儿交集、并集、差集的操作,比如交集吧,可以把两个人的粉丝列表整一个交集,看看俩人的共同好友是谁?对吧。
把两个大 V 的粉丝都放在两个 set 中,对两个 set 做交集。
#-------操作一个set-------
# 添加元素
sadd mySet 1
# 查看全部元素
smembers mySet
# 判断是否包含某个值
sismember mySet 3
# 删除某个/些元素
srem mySet 1
srem mySet 2 4
# 查看元素个数
scard mySet
# 随机删除一个元素
spop mySet
#-------操作多个set-------
# 将一个set的元素移动到另外一个set
smove yourSet mySet 2
# 求两set的交集
sinter yourSet mySet
# 求两set的并集
sunion yourSet mySet
# 求在yourSet中而不在mySet中的元素
sdiff yourSet mySet
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 底层
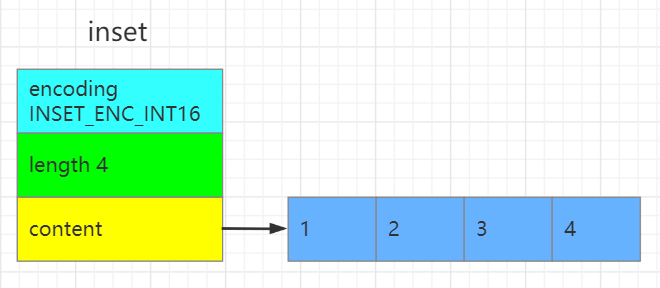
与Java中的HashSet一样,无序且存储元素不重复。其底层有两种实现方式,当value是整数值时,且数据量不大时使用inset来存储,其他情况都是用字典dict来存储。
typedf struct inset{
uint32_t encoding;//编码方式 有三种 默认 INSET_ENC_INT16
uint32_t length;//集合元素个数
int8_t contents[];//实际存储元素的数组
//元素类型并不一定是ini8_t类型,柔性数组不占intset结构体大小,并且数组中的元
//素从小到大排列
}inset;
//16位,2个字节,表示范围-32,768~32,767
#define INTSET_ENC_INT16 (sizeof(int16_t))
//32位,4个字节,表示范围-2,147,483,648~2,147,483,647
#define INTSET_ENC_INT32 (sizeof(int32_t))
//64位,8个字节,表示范围-9,223,372,036,854,775,808~9,223,372,036,854,775,807
#define INTSET_ENC_INT64 (sizeof(int64_t))
2
3
4
5
6
7
8
9
10
11
12
13
推荐阅读:Redis底层数据结构之set (opens new window)
# Sorted Sets
# 介绍
Sorted Sets 是排序的 set,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
zadd board 85 zhangsan
zadd board 72 lisi
zadd board 96 wangwu
zadd board 63 zhaoliu
# 获取排名前三的用户(默认是升序,所以需要 rev 改为降序)
zrevrange board 0 3
# 获取某用户的排名
zrank board zhaoliu
2
3
4
5
6
7
8
9
10
# 实现
sortedset同时会由两种数据结构支持,ziplist和skiplist.
只有同时满足如下条件是,使用的是ziplist,其他时候则是使用skiplist
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
当ziplist作为存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表结点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值.
当使用skiplist作为存储结构时,使用skiplist按序保存元素分值,使用dict来保存元素和分值的对应关系