 Impala 介绍
Impala 介绍
# 概述
Impala 是一个架构于 hadoop 之上的全新、开源 MPP 查询引擎,提供低延迟、高并发的以读为主的查询。
Impala 提升了查询性能,又保留了用户熟悉的操作。通过 Impala,你可以使用 SELECT、JOIN 和聚集函数等语法,实时地查询储存在 HDFS 或 HBase 上的数据。除此之外,Impala 使用 Hive 的元数据库、SQL 语法,ODBC 驱动及用户界面,提供一个友好、统一的平台进行批处理或实时查询。因此,Hive 用户能够很方便的使用 Impala。
# 架构
为了避免延迟,Impala 摒弃了 MapReduce 引擎,借鉴 MPP 并行数据库的思想,使用一个专用的、分布式的查询引擎直接访问数据。依据查询的类型和配置,与 Hive 相比较,性能有数量级的提升。
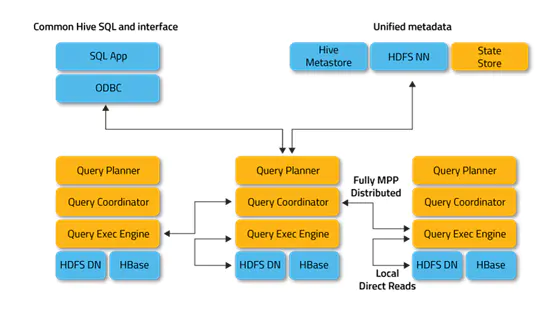
由架构图可以看出查询的执行过程:
- 由 Client 发送一个执行 SQL 到任意一台 Impalad 的 Query Planner
- 由 Query Planner 把 SQL 发向 Query Coordinator
- 由 Query Coordinator 来调度分配任务到 Impalad 的所有节点
- 各个 Impalad 节点的 Query Executor 进行执行 SQL 工作
- 执行 SQL 结束以后,将结果返回给 Query Coordinator
- 再由 Query Coordinator 将结果返回给 Client
# 服务组件
Impala 由三个核心服务构成:Statestored、Catalogd、Impalad。
- Statestored: 一个实例。Statestore daemon 负责收集分布在集群中各个 impalad 进程的资源信息,各节点健康状况,同步节点信息,负责 query 的调度。
- Catalogd: 一个实例。Catalog daemon 负责接收来自 Statestored 的所有请求,把 impala 的 metadata 分发到各个 impalad。
- Impalad: N 个实例。Impala daemon 运行在 1 个或多个节点上,与 Statestored 保持通信,负责接收客户端的请求并返回结果。
Impala 没有主节点,Statestored 与 Catalogd 具有主节点的功能,可当作主节点,Impalad 可理解为从节点。
# 特点
Impala 提供对 HDFS、HBase 数据的高性能、低延迟的交互式 SQL 查询,基于 Hive 并使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点。具体特点:
- 基于内存进行计算,能够对 PB 级数据进行交互式实时查询、分析
- 直接读取 HDFS 数据,完全抛弃 MapReduce,省掉了作业启动的开销;借鉴 MPP 并行数据库的思想,省掉了 shuffle、sort 等开销;中间结果不落地,省掉了大量的 IO 开销。
- C++编写,LLVM 统一编译运行
- 兼容 HiveSQL
- 具有数据仓库的特性,可对 Hive 数据直接做数据分析
- 支持 Data Local
- 支持列式存储
- 支持 JDBC/ODBC 远程访问
基于这些特点,Impala 是 CDH 平台首选的 PB 级大数据实时查询分析引擎。
另外,Impala 也有一些劣势,比如对内存依赖大、过于依赖 Hive 等,使用上也有其他的限制,具体限制参考官方文档。但这不足以影响 Impala 良好的实时查询分析特点。
在 GitHub 编辑此页 (opens new window)
上次更新: 2024/02/25, 12:11:11